Матричные микропроцессоры можно рассмотреть с двух сторон: на уровне транзисторных матриц и матриц процессоров.
Использование матриц при проектировании процессоров может быть двухсторонним: матрицы транзисторов для проектирования микропроцессоров и матрицы микропроцессоров для проектировании процессорных систем.
Использование матриц при построении процессорных систем не ограничивается соединением процессоров по конвейерному принципу. Подобную архитектуру можно использовать также и при проектировании ИС с использованием транзисторных матриц, выполненных по МОП-технологии. Рассмотрим оба варианта применения матриц.
ТРАНЗИСТОРНЫЕ МАТРИЦЫ
Сокращение сроков проектирования микропроцессоров и повышение надежности проектов требуют применения соответствующих систем автоматизации проектирования. Одним из самых перспективных направлений в настоящее время считается подход к сквозной автоматизации проектирования, называемой кремниевой компиляцией, позволяющий исходное задание на проектирование - функциональное описание, представленное на языке высокого уровня, преобразовать в топологические чертежи. Кремниевые компиляторы используют в качестве базовых регулярные матричные структуры, хорошо приспособленные к технологии СБИС. Большое распространение получили программируемые логические матрицы (ПЛМ) и их различные модификации. Они ориентированы на матричную реализацию двухуровневых (И, ИЛИ) логических структур, а также для оптимизации их параметров (площади, быстродействия) известны различные методы. Реализация многоуровневых логических структур СБИС часто опирается на матричную топологию: в этом случае компиляторы генерируют топологию по ее матричному описанию.
Транзисторные матрицы
Особым стилем реализации топологии в заказных КМОП СБИС являются транзисторные матрицы. В лэйауте (англ. layout - детальное геометрическое описание всех слоев кристалла) транзисторных матриц все p-транзисторы располагаются в верхней половине матрицы, а все n-транзисторы - в нижней. Транзисторные матрицы имеют регулярную структуру, которую составляют взаимопересекающиеся столбцы и строки. В столбцах матрицы равномерно расположены полосы поликремния, образующие взаимосвязанные затворы транзисторов. По другим полюсам транзисторы соединяются друг с другом сегментами металлических линий, которые размещаются в строках матрицы. Иногда, для того чтобы соединить сток и исток транзисторов, находящихся в различных строках, вводят короткие вертикальные диффузионные связи. В дальнейшем ТМ будет представляться абстрактным лэйаутом.
Абстрактный лэйаут - схематический рисунок будущего кристалла, где прямоугольники обозначают транзисторы, вертикальные линии - поликремниевые столбцы, горизонтальные - линии металла, штриховые - диффузионные связи, точки - места контактов, стрелки - места подключения транзисторов к линиям Gnd и Vdd. При переходе к послойной топологии стрелки должны быть заменены полосками в диффузионном слое, по которому осуществляются соединения между строками ТМ.
На рис. 1.а представлена транзисторная схема, а на рис. 1.б - транзисторная матрица, реализующая данную схему.
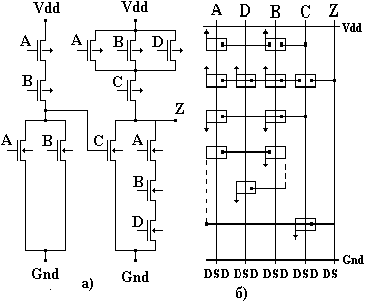
Символическое представление топологии транзисторных матриц.
Одной из завершающих стадий получения топологии транзисторных матриц является переход от символического лэйаута к топологическому описанию схемы на уровне слоев. Символические лэйауты конструируются путем размещения символов не решетке, которая служит для создания топологии заданной схемы. Каждый символ представляет геометрию, которая может включать любое число масочных уровней. Схемотехника транзисторных матриц позволяет использовать небольшое число различных символов, требуемых для описания лэйаута:
N - n-канальный транзистор;
P - p-канальный транзистор;
+ - надпересечение - металл над диффузией; металл над поликремнием; пересекающиеся вертикальный и горизонтальный металлы;
![]() - контакт (к поликремнию либо диффузии);
- контакт (к поликремнию либо диффузии);
! - p-диффузия;
![]() - n-диффузия, либо поликремний;
- n-диффузия, либо поликремний;
: - металл в вертикальном направлении;
![]() - металл в горизонтальном направлении.
- металл в горизонтальном направлении.
Каждый символ транзистора соответствует транзистору минимального размера. Однако ширина канала может увеличиваться многократным повторением символа. Только один символ “+” требуется для того, чтобы обозначить пересечение всех трех уровней взаимосвязей: а именно, металл над диффузией, металл над поликремнием и пересекающийся вертикальный и горизонтальный металлы. Символ контакта “![]() ” используется для того, чтобы определить контакт металла к поликремнию или диффузии. Символ “
” используется для того, чтобы определить контакт металла к поликремнию или диффузии. Символ “![]() ” используется для представления либо поликремниевых, либо n-диффузионных проводников. Символ для диффузии p-типа “!” требуется для различия ее от диффузии n-типа, которая может существовать в том же столбце. Символы для металла “:” либо “-” обозначают вертикальные или горизонтальные линии металла соответственно. На рис. 1.в. дано символьное представление лэйаута транзисторной матрицы, а на рис. 1.г. - заключительный лэйаут.
” используется для представления либо поликремниевых, либо n-диффузионных проводников. Символ для диффузии p-типа “!” требуется для различия ее от диффузии n-типа, которая может существовать в том же столбце. Символы для металла “:” либо “-” обозначают вертикальные или горизонтальные линии металла соответственно. На рис. 1.в. дано символьное представление лэйаута транзисторной матрицы, а на рис. 1.г. - заключительный лэйаут.
Если логическая схема построена на базе элементов, для которых нет транзисторных описаний в библиотеках, то возникает сложная задача получения требуемых представлений схемы, особенно, когда имеются дополнительные требования к параметрам - площади, быстродействию и т.д. Задача перехода от логического описания комбинационной логики в одном базисе к описанию в другом базисе в настоящее время решается по нескольким направлениям.
Глобальная оптимизация. Сначала осуществляется переход к системе дизъюнктивных нормальных форм (ДНФ), которая обычно минимизируется, а затем представляется в виде многоуровневой логической сети, реализуемой в требуемом базисе. Основная оптимизация ведется при построении многоуровневой сети - обычно это сеть в базисе И, ИЛИ, НЕ, а основным критерием сложности является критерий числа литералов (букв) в символическом (алгебраическом) представлении булевых функций. Методы оптимизации опираются либо на функциональную декомпозицию, либо на факторизацию (поиск общих подвыражений) в алгебраических скобочных представлениях функций, реализуемых схемой. Заключительный этап - реализацию в требуемом базисе принято называть технологическим отображением. Именно на этом этапе можно оценить максимальную задержку схемы - задержку вдоль критического пути. Предполагается, что в узлах схемы установлены базисные элементы.
Локальная оптимизация. Замена одних базисных логических операторов другими осуществляется путем анализа локальной области схемы. Поиск фрагментов и правила их замены другими может осуществляться с помощью экспертной системы. Так, например, устроена система LSS.
Подробно обзор многих методов оптимизации многоуровневых логических схем приведен в [0].
МАТРИЧНЫЕ ПРОЦЕССОРЫ
Матричные процессоры наилучшим образом ориентированы на реализацию алгоритмов обработки упорядоченных (имеющих регулярную структуру) массивов входных данных. Они появились в середине 70-х годов в виде устройств с фиксированной программой, которые могли быть подключены к универсальным ЭВМ; но к настоящему времени в их программирования достигнута высокая степень гибкости. Зачастую матричные процессоры используются в качестве вспомогательных процессоров, подключенных к главной универсальной ЭВМ. В большинстве матричных процессоров осуществляется обработка 32-х разрядных чисел с плавающей запятой со скоростью от 5000000 до 50000000 флопс. Как правило они снабжены быстродействующими портами данных, что дает возможность для непосредственного ввода данных без вмешательства главного процессора. Диапазон вариантов построения матричных процессоров лежит от одноплатных блоков, которые вставляются в существующие ЭВМ, до устройств, конструктивно оформленных в виде нескольких стоек, которые по существу представляют собой конвейерные суперЭВМ.
Типичными видами применения матричных процессоров является обработка сейсмической и акустической информации, распознавание речи; для этих видов обработки характерны такие операции, как быстрое преобразование Фурье, цифровая фильтрация и действия над матрицами. Для построения относительно небольших более экономичных в работе матричных процессоров используются разрядно-модульные секции АЛУ в сочетании с векторным процессором, основанном на основе биполярного СБИС-процессора с плавающей запятой.
Вероятно, в будущем матричные процессоры будут представлять собой матрицы процессоров, служащие для увеличения производительности процессоров сверх пределов, установленных шинной архитектурой.
Для реализации обработки сигналов матрицы МКМД могут быть организованы в виде систолических или волновых матриц.
Систолическая матрица состоит из отдельных процессорных узлов, каждый из которых соединен с соседними посредством упорядоченной решетки. Большая часть процессорных элементов располагает одинаковыми наборами базовых операций, и задача обработки сигнала распределяется в матричном процессоре по конвейерному принципу. Процессоры работают синхронно, используя общий задающий генератор тактовых сигналов, поступающий на все элементы.
В волновой матрице происходит распределение функций между процессорными элементами, как в систолической матрице, но в данном случае не имеет места общая синхронизация от задающего генератора. Управление каждым процессором организуется локально в соответствии с поступлением необходимых входных данных от соответствующих соседних процессоров. Результирующая обрабатывающая волна распространяется по матрице по мере того, как обрабатываются входные данные, и затем результаты этой обработки передаются другим процессорам в матрице.
АВТОМАТИЗАЦИЯ ПРОЕКТИРОВАНИЯ ЦИФРОВЫХ СБИС НА БАЗЕ МАТРИЦ ВАЙНБЕРГЕРА И ТРАНЗИСТОРНЫХ МАТРИЦ
Введение. Все большую долю в общем объеме ИС составляют заказные цифровые ИС, выполненные в основном, по МОП-технологии. Сокращение сроков проектирования и повышение надежности проектов требуют применения соответствующих систем автоматического проектирования. Одним из самых перспективных направлений в настоящее время считается подход к сквозной автоматизации проектирования, называемой кремниевой компиляцией, позволяющей исходное задание на проектирование - функциональное описание, представленное на языке программирования высокого уровня, преобразовать в топологические чертежи. Кремниевые компиляторы используют в качестве базовых регулярные матричные структуры, хорошо приспособленные к технологии СБИС. Большое распространение получили программируемые логические матрицы (ПЛМ) и их различные модификации. Они ориентированы на матричную реализацию двухуровневых (И, ИЛИ) логических структур, а также для оптимизации их параметров (площади, быстродействия) известны различные методы.
Заключительный этап - реализацию в требуемом базисе принято называть технологическим отображением. Именно на этом этапе можно оценить максимальную задержку схемы - задержку вдоль критического пути. Предполагается, что в узлах схемы установлены базисные элементы.
Локальная оптимизация. Замена одних базисных логических операторов другими осуществляется путем анализа локальной области схемы. Поиск фрагментов и правила их замены другими может осуществляться с помощью экспериментальной системы. Так, например, устроена система LSS.
Оптимизация МВ на логическом уровне представляет более простую задачу. На этом этапе обычно минимизируется число операторов f = k1 V ... V kl - по существу число столбцов МВ. Минимизация числа строк происходит на этапе топологического проектирования.
Подробно обзор многих методов оптимизации многоуровневых логических схем приведена в [4]. Заключая данный раздел, можно сказать, что актуальной проблемой является проблема разработки методов оптимизации многоуровневых структур с учетом последующей базовой топологической реализации. Проблема осложняется тем, что нужно выработать еще соответствующие критерии оптимизации. Если для ПЛМ критерий минимальности числа термов адекватен сложности последующей топологической реализации, то для МВ и, особенно для ТМ, типичной дилеммой при минимизации площади является следующая - провести дополнительную связь, либо установить дополнительный элемент. Может оказаться так, что сильная связность схемы может быть неприемлемой из-за больших затрат площади кристалла под соединения элементов.
Заключение. В обзоре представлены основные подходы к проектированию структур заказных цифровых СБИС на базе основных моделей матриц Вайнбергера и транзисторных матриц.
Модификация основной модели МВ, когда снимаются требования подключения каждого столбца к линии “земли”; реализация каждой переменной только в одной стоке матрицы; невозможности дублирования линий “земли” и нагрузки; приводит к новым формальным постановкам задач оптимизации параметров МВ, хотя и для основной модели не все проблемы решены - открыта, например, проблема синтеза МВ с заданным быстродействием.
Таким образом, важнейшими проблемами, решаемыми в настоящее время для МВ и ТМ, являются проблемы разработки формальных методов синтеза, которые позволяли бы гибко оптимизировать такие характеристики, как площадь, быстродействие, габариты, электрические параметры схем. Данные проблемы в настоящее время актуальны не только для МВ и ТМ - подобные проблемы находятся в центре внимания разработчиков САПР заказных цифровых СБИС и применительно к другим базовым структурам.
Матричные процессоры
Матричные процессоры наилучшим образом ориентированы на реализацию алгоритмов обработки упорядоченных (имеющих регулярную структуру) массивов входных данных. Они появились в середине 70-ых годов в виде устройств с фиксированной программой, которые могли быть подключены к универсальным ЭВМ; но к настоящему времени в их программировании достигнута высокая степень гибкости. Зачастую матричные процессоры используются в качестве вспомогательных процессоров, подключаемых к главной универсальной ЭВМ. В большинстве матричных процессоров осуществляется обработка 32 разрядных циклов с плавающей запятой со скоростью от 5000000 до 50000000 флопс. Как правило, они снабжены быстродействующими портами данных, что дает возможность для непосредственного ввода данных без вмешательства главного процессора. Диапазон вариантов построения матричных процессоров лежит от одноплатных блоков, которые вставляются в существующие ЭВМ до устройств, конструктивно оформленных в виде нескольких стоек, которые по существу представляют собой конвейерные суперЭВМ.
Типичными видами применения матричных процессоров является обработка сейсмической и акустической информации, распознавание речи; для этих видов обработки характерны такие операции, как быстрое преобразование Фурье, цифровая фильтрация и действия над матрицами. Для построения относительно небольших более экономичных в работе матричных процессоров используются разрядно-модульные секции АПУ в сочетании с векторным процессором, реализованным на основе биполярного СБИС-процессора с плавающей запятой.
Вероятно, в будущем матричные процессоры будут представлять собой матрицы процессоров, служащие для увеличения производительности процессоров сверх пределов, установленных шинной архитектурой.
Главным архитектурным различием между традиционными ЭВМ, предназначенными для обработки научной и коммерческой информации, является то, что последние (мини-, супермини-, универсальные и мега-универсальные ЭВМ) имеют главным образом скалярную архитектуру, а машины для научных расчетов (супер-, минисупер-ЭВМ и матричные процессоры) - векторную. Скалярная ЭВМ (рис. 1.) имеет традиционную фон-неймановскую, то есть SISD-организацию, для которой характерно наличие одной шины данных и последовательное выполнение обработки одиночных элементов данных. Векторная машина (рис. 2.) имеет в своем составе раздельные векторные процессоры или конвейеры, и одна команда выполняется в ней над несколькими элементами данных (векторами)
Векторные архитектуры - это в основном архитектуры типа SISD, но некоторые из них могут относиться к классу MIMD. Векторная обработка увеличивает производительность процессорных элементов, но не требует наличия полного параллелизма в ходе обработки задачи.
Для реализации обработки сигналов матрицы МЛМД могут быть реализованы в виде систолических или волновых матриц.
Систолическая матрица состоит из отдельных процессорных узлов, каждый из которых соединен с соседним посредством упорядоченной решетки. Большая часть процессорных элементов располагает одинаковыми наборами базовых операций, и задача обработки сигнала распределяется в матричном процессоре по конвейерному принципу. Процессоры работают синхронно, используя общий задающий генератор тактовых сигналов, поступающий на все элементы.
В волновой матрице происходит распределение функций между процессорными элементами, как в систолической матрице, но в данном случае не имеет места общая синхронизация от задающего генератора. Управление каждым процессором организуется локально в соответствии с поступлением необходимых входных данных от соответствующих соседних процессоров. Результирующая обрабатывающая волна распространяется по матрице по мере того, как обрабатываются входные данные, и затем результаты этой обработки передаются другим процессорам в матрице.
МКМД (множественный поток команд, множественный поток данных.) Множественный поток команд предполагает наличие нескольких процессорных узлов и, следовательно, нескольких потоков данных. Примерами такой архитектуры являются мультипроцессорные матрицы.
Транспьютер Inmos Т414 предназначен для построения МКМД структур; для обмена информацией с соседними процессорами в нем предусмотрены четыре быстродействующие последовательных канала связи. Имеется встроенная память большой емкости, которая может быть подключена к интерфейсу шины памяти. Разрядность местной памяти каждого транспьютера наращивает разрядность памяти системы; таким образом, полная разрядность памяти пропорциональна количеству транспьютеров в системе. Суммарная производительность также возрастает прямо пропорционально числу входящих в систему транспьютеров.
В дополнение к параллельной обработке, реализуемой транспьютерами, предусмотрены специальные команды для разделения процессорного времени между одновременными процессорами и обмена информацией между процессорами. Хотя программирование транспьютеров может выполняться на обычных языках высокого уровня, для повышения эффективности параллельной обработки был разработан специальный язык Okkam.
Транзисторные матрицы (ТМ) являются одной из популярных структур для проектирования топологии макроэлементов заказных цифровых СБИС, выполняемых по КМОП-технологии, ТМ имеют регулярную матричную топологию, получение которой может быть автоматизировано, что привлекает к ним разработчиков кремниевых компиляторов. Известные методы проектирования ТМ ориентированы на минимизацию площади кристалла, занимаемую информационными транзисторами, и оставляет в стороне вопрос о минимизации площади, требуемой для разводки шин “земли” (Gnd) и “питания” (Vdd). В данной статье предлагается метод минимизации числа шин Gnd и Vdd в ТМ, после того, как ее площадь была минимизирована с помощью методов [4,5].
Структура ТМ.
В лэйауте (англ. layout - детальное геометрическое описание всех слоев кристалла) транзисторных матриц все p-транзисторы располагаются в верхней половине матрицы, а все n-транзисторы - в нижней. Транзисторные матрицы имеют регулярную структуру, которую составляют взаимопересекающиеся столбцы и строки. В столбцах матрицы равномерно расположены полосы поликремния, образующие взаимосвязанные затворы транзисторов. По другим полюсам транзисторы соединяются друг с другом сегментами металлических линий, которые размещаются в строках матрицы. Иногда, для того чтобы соединить сток и исток транзисторов, находящихся в различных строках, вводят короткие вертикальные диффузионные связи. В дальнейшем ТМ будет представляться абстрактным лэйаутом.
Абстрактный лэйаут - схематический рисунок будущего кристалла, где прямоугольники обозначают транзисторы, вертикальные линии - поликремниевые столбцы, горизонтальные - линии металла, штриховые - диффузионные связи, точки - места контактов, стрелки - места подключения транзисторов к линиям Gnd и Vdd. При переходе к послойной топологии стрелки должны быть заменены полосками в диффузионном слое, по которому осуществляются соединения между строками ТМ. Очевидно, что подведению вертикальных связей к линиям Gnd, Vdd могут препятствовать транзисторы, расположенные в других строках транзисторной матрицы, либо расположенные в тех же столбцах диффузионные связи между строками (горизонтальные линии металла не являются препятствием). В следствие этого приходится размещать несколько линий Gnd в n-части ТМ и несколько линий Vdd в p-части ТМ. Возникает задача минимизации числа этих линий. Будем рассматривать ее только для n-части ТМ, задача минимизации числа линий Vdd для p-части ТМ решается аналогичным образом.
Пример абстрактного лэйаута для КМОП-схемы (рис. 1.а.) показан на рис. 1.б.
Формализация задачи.
Пусть транзисторная матрица размером n на m задана абстрактным лэйаутом. Представим последний троичной матрицей S размером n на 2m, поставим ее строки в соответствие строкам ТМ, а пары соседних столбцов - столбцам ТМ. Таким образом, каждый элемент матрицы S представляет некоторую позицию лэйаута и получает значение 1, если там стоит стрелка, значение 0 - если там не показан ни транзистор, ни диффузионная связь, и значение * - в остальных случаях. Легко видеть, что значение * свидетельствует о невозможности проведения через данную точку диффузионной связи от стока некоторого транзистора к линии Gnd.